Skills
Game/App Development (Unity)
Developing & Publishing games (Full work cycle)
3D Solid Modeling (Blender)
Hard Surface Modeling, Rigging & Animation; UV Unwrapping & creating Material Node Setup
Visual Effects (AE + Unity)
Adobe’s After Effects, Unity’s Shuriken Particle System & VFX Graph
App Downloads
Indie Projects
Client Projects
Average Rating
Portfolio

Flip the bottle Challenge in UnityML
Unity ML learns to flipping the bottle. Agent is rewarded for higher rotation and extra reward if bottle stands on the ground after the throw attempt. Working Video

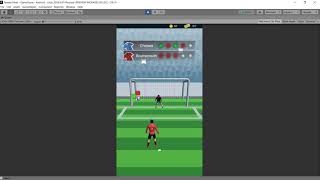
Penalty Fever: A Penalty Shootout Game
It is a client project. Check the below video for working. Working Video

3D Modeling App (Android/iOS)
You can now make 3D Models and do 3D Animation straight from your mobile phones. The app is currently is closed beta and undergoing testing. The open beta version will be released on October 2019, and will be free at the respective Android/iOS marketplace. Initial Phase – Creating a simple UI was at priority. Layouts…

Passenger getting on/off Indian Railway (Simulation)
This was a project for one of my clients. He wanted to see passengers load on/off train. He required an Indian-styled train, so I made one for him in Blender. Later, A* path finding was implemented in Unity. Modeling + Scripting – The complete simulation was scripted for the project. Below video mainly covers the…

Idle Clicker Race Game
This was a project for one of my clients. A prototype of the game ‘Idle Tap Racing’ by Neon Play. This project is an idle clicker game. Scripting – The complete UI as well as all below things were scripted for the project. Below video shows the entire workflow of the game.

Emergency Situations Simulation in Unity
This was a client project to depict ‘Uphaar Cinema’s’ fire which happened in 1997 in Greek Park, Delhi and also show possible solutions so that the disaster wouldn’t have happened. Trapped inside, 59 people died, mostly due to suffocation, and 103 were seriously injured in the resulting stampede. Initial Phase – So various possible solutions to this…

Find the Difference in 3D Models
Object of difference in a particular scene DON’T REMAIN SAME. So, you can play the same level again and again, because every time you will see new difference. Includes total of 25 levels. [Android App Link] Initial Phase – Cartoony 3D models with lot of stuff in it. Scripting – Nothing fancy. There are two…

Hook Pro 5v5 Game Development (inspired from Dota2’s Arcade)
Hook Pro 5v5 is a 5 versus 5 game. Player controls a Pudge (Butcher) Character with various spell to use like: Meat Hook. The two teams faces off on a rectangular map divided by an uncross-able division. This game is inspired from Valve Corp.’s DOTA2 Arcade Game ‘Pudge Wars’ and ‘1 Hook 1 Kill’. [Android…

Counter Strike Guns Skin Creator App
Create Counter Strike Global Offensive Skins by painting on 3D Weapon Models. This is more simple than coloring on 2D UV marked images which the professionals do. You have the 3D Model. Just paint on it and get the 2D Image as Skin Output. You can create skin and send it to Valve for inclusion…
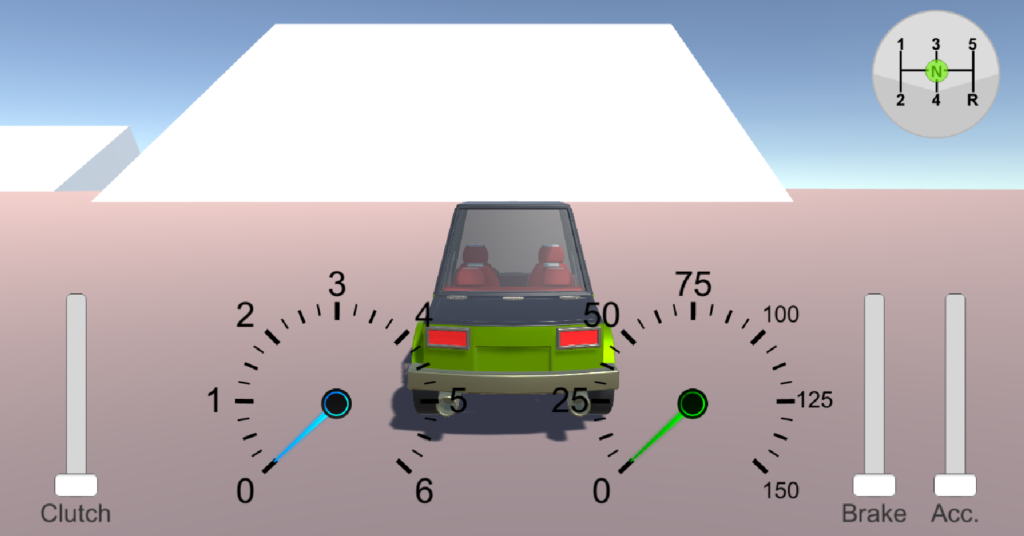
Manual Car Driving Mechanism
This game is a simulation of real world driving, where you need precise control over Clutch, Accelerator and Brake to drive without any halt and increase car’s economy. Majority of the time on this project is spent in building the mechanics of the entire gearbox/clutch system. The project was done as a part of challenge…
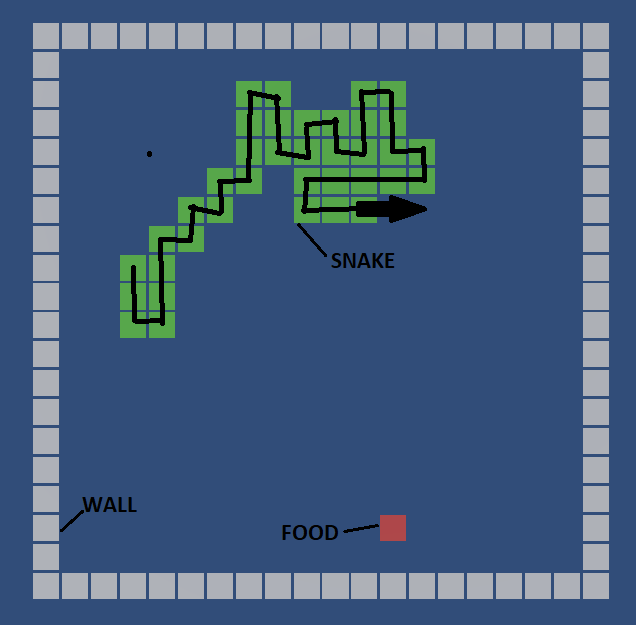
Snakes – Unity ML Agent
[NOTE: This includes entire workflow of Unity ML Agent. Refer: https://github.com/Unity-Technologies/ml-agents] Snake Movement Mechanism Most important thing in the snake movement is considering that there is cube movement and not snake movement as a whole body. The trick here is: instead of make all snake body cubes transform as snake moves, it will better to…