Snakes – Unity ML Agent
[NOTE: This includes entire workflow of Unity ML Agent. Refer: https://github.com/Unity-Technologies/ml-agents]
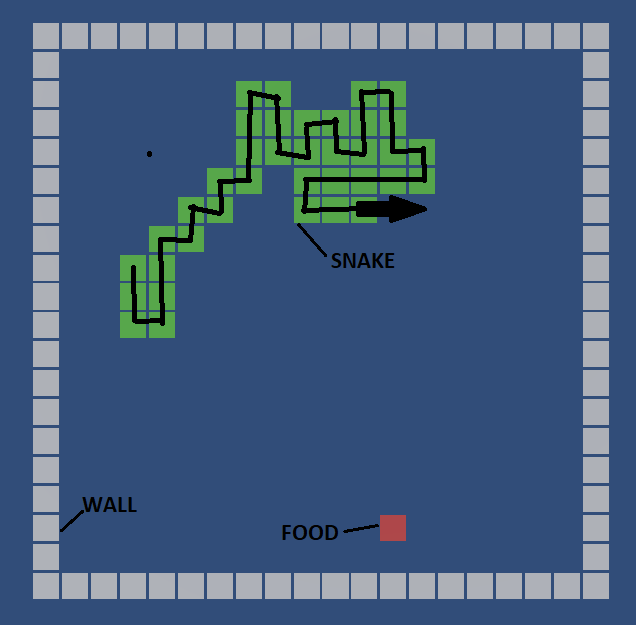
- Snake Movement Mechanism
Most important thing in the snake movement is considering that there is cube movement and not snake movement as a whole body. The trick here is: instead of make all snake body cubes transform as snake moves, it will better to take the snake tail cube out and make it as a new step head. Using “linkedlist” to pull out last element and push to the first.
- Collect Observations that are required for equation formulation
public override void CollectObservations() //Collect variables that will be useful for snake to learn and form a learning equation
{
AddVectorObs(sm.currentHeadT.position.x - food.transform.position.x); //Difference of snake head and food along x-component
AddVectorObs(sm.currentHeadT.position.y - food.transform.position.y); //Difference of snake head and food along y-component
AddVectorObs(sm.currentDir); //The direction the snake is heading //(1,0)~right, (0,-1)~down,etc.
}
- Rewarding the Snake
Reward Snake for all the right thing it does. Like moving towards the food. For example,
float A = Mathf.Abs(foodp.x - headp.x); // "foodp" is position of food // "headp" is position of snake head float B = Mathf.Abs(foodp.y - headp.y); AddReward(0.001f - (0.00001f * (A + B))); //more closer the head to the food, more is the reward
Give high reward for eating food. Take away reward for self collision or hitting the wall, so it knows that something he is doing is wrong.
- Run the Training (Tensor-flow + Anaconda Prompt)
After completing the learning for some 400,000 steps, we have the following results,

The “losses” graph suggests that the agent has decently learned what it was supposed to learn. The snake still continues to self collide. It does avoid walls (when observation is included with absolute current position of snake head). It eats food as it is told to. According to the graph of “Environment/Cumulative Reward”, the graph goes down after reaching the peak at 100,000 steps because it starts learning the fact that self collision takes away reward. Initially it was earning reward when coming close to food and eating it. Later as snake learned more, it grew bigger, increasing the probability of self collision, in turn decreasing the reward.